The Hidden Data Center Bottleneck
As NVIDIA prepares to release Blackwell, it's important that we take a step back and realize that it's important to optimize the server rack just as much as the GPU.

The GPU Bottleneck Problem
A few weeks ago, I listened to the Invest Like the Best podcast, where Gavin Baker, an industry legend in tech and semiconductors, made a statement that caught my attention:
“The big problem in the data center, particularly over the last five years, is that GPUs have gotten 50x faster, but the rest of the data center—memory, storage, networking, and CPUs—has only improved 4x to 5x. MFU (Maximum GPU Utilization) is so low because the GPU is sitting around, waiting for all those things to do their job. It’s doing nothing most of the time.”
In a world obsessed with the coming release of NVIDIA’s new GPU Blackwell, it’s surprising to hear that the real bottleneck lies within the data center. The challenge is not the GPU itself, but the rest of the data center infrastructure, which struggles to keep up with the GPU’s rapid advances.
In this article, I plan to:
Define and analyze relevant metrics that help track GPU efficiency
Quantify the bottleneck mentioned by Baker using growth in efficiency on all parts of the server rack
Identify the market of promising startups trying to solve this problem
To start, however, there’s a metric that is important for us to know to truly understand GPU efficiency called Model Flops Utilization (MFU).
What is MFU?
This metric represents how efficiently a GPU is being used in relation to its theoretical maximum performance, measured in floating-point operations per second (FLOPs). Essentially, MFU tells us how much of the GPU’s computational power is being used during a given task.
For example, let’s say a GPU is theoretically capable of 100 teraflops (100 trillion floating-point operations per second). If, during a workload, the GPU is only performing 50 teraflops, then the MFU is 50%. This means that half of the GPU’s potential is going unused, often because other components in the data center are not delivering data fast enough for the GPU to process efficiently, or the computations have errors.
Why Does MFU Matter?
MFU is a critical metric, especially as modern GPUs, like those from NVIDIA and AMD, have become extremely powerful. If the surrounding data center infrastructure is not optimized, the GPUs will not reach their full potential, leading to inefficiencies and wasted resources. I think Baker sums this one up well:
“If you have a higher MFU, it means that you can choose for the same amount of money you were spending, you have the same amount of GPUs and the similar amount of power presumably, you could choose between faster time to market. If you were at a 50% MFU and your competitor is running 40%, for an equivalent amount of training FLOPS, you could be at market 45% faster. You could choose between better quality... you can make a model lower cost in a variety of ways”
The current average MFU for AI Model Training sits around 35-40%, which suggests tons of room for improvement in all areas of the server rack.
Thus, we need to look beyond GPUs to understand what’s stalling server rack and GPU performance. Data centers rely on several components—networking, memory, storage, and CPUs—that must work together seamlessly. While GPUs have seen extraordinary performance gains, innovation and investment in these supporting technologies haven’t matched that pace. Let’s illustrate that now.
Innovation in Memory, Networking, and Storage
To evaluate innovation since 2015, I’ve chosen key metrics for memory, storage, and networking, which help us understand the performance gains in each area.
Memory (Data Rate per Pin)
Memory bandwidth, typically measured in GB/sec, reflects how fast data can be transferred within a system. Higher data rates mean faster data transmission, crucial for applications like high-performance computing (HPC), AI, and even gaming.
Storage (Throughput)
Storage throughput, also in GB/sec, affects how quickly data can be read from or written to storage devices such as SSDs. Efficient storage systems minimize the idle time for GPUs, ensuring they aren’t left waiting for data before performing computations.
Networking (Bandwidth)
Network bandwidth, measured in GB/sec, governs how quickly data moves between different GPUs or compute nodes. High bandwidth reduces latency and enables GPUs to collaborate effectively in large-scale tasks, such as AI training.
Plotting the Improvement
Let’s start by plotting the improvement in each since 2015.
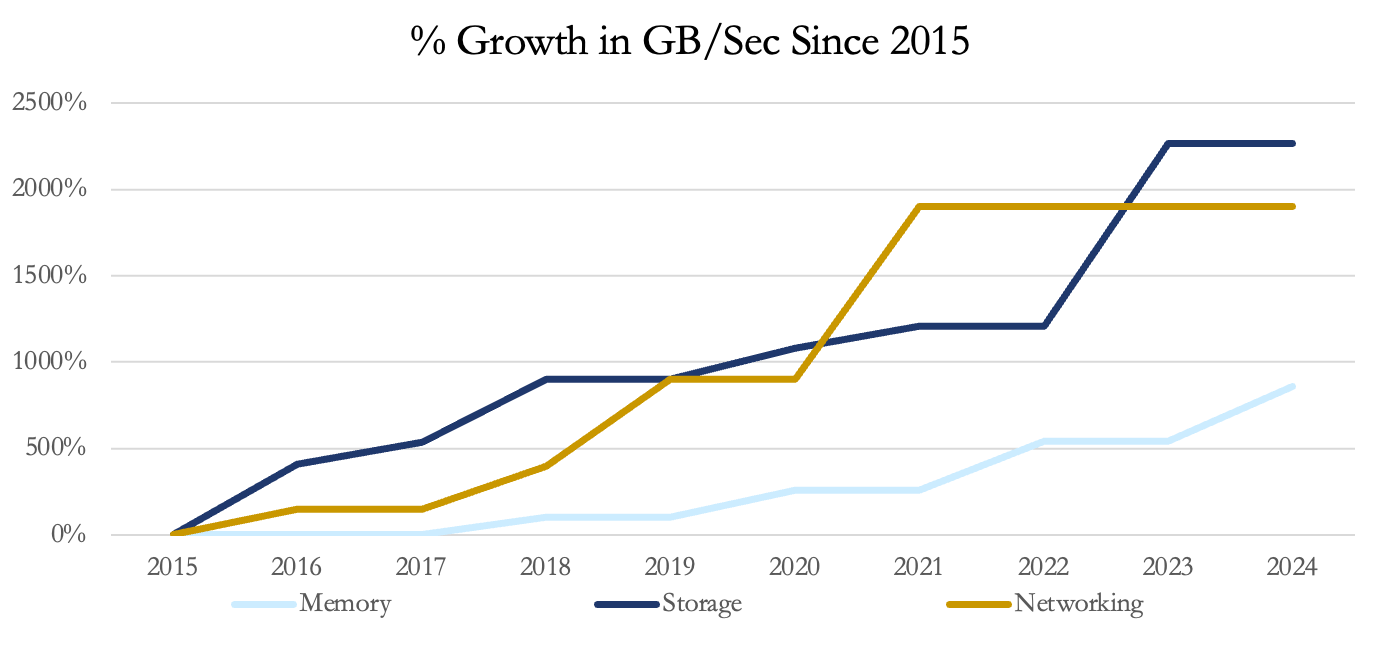
Storage systems, particularly SSDs, have increased throughput by more than 20x, and networking bandwidth has grown nearly as much. Memory performance has seen substantial growth as well, with data rates improving by almost 900%—memory sticks now operate at 9.6 gigabits per second per pin, also almost a 20x increase in performance in 10 years.
Memory has gone through five different models of HBM (High-bandwidth memory) since 2015 developed by key players Samsung, Micron, and SK Hynix, with the leading model currently being called HBM3E with data rates at 9.6 GB/sec, 900% better than 2015.
New SSDs have been developed by Micron, Samsung, and Intel, now with leading models like the Samsung PM9A3 containing throughput rates of 13 GB/sec, representing an improvement of > 2,000% in 9 years.
Networking bandwidth has increased significantly, advancing from around 40 Gbps to 800 Gbps, with future speeds expected to reach 1.6 Tbps, driven by industry leaders like NVIDIA and Arista Networks.
While these improvements are already incredible, the GPU’s improvements are incredibly exciting too which we’ll now view.
Compared to the GPU…
What we’ll be analyzing - FP16 Compute Power
To track GPU performance over the last 9 years, we will use a metric called FP16, measured in Teraflops. FP16 (and Tensor FP16 for NVIDIA) refers to how a computer's graphics processing unit (GPU) handles mathematical operations, especially those involving tensors, which are large collections of numbers (like grids or arrays) used in things like artificial intelligence and machine learning.
Teraflops (TFLOPs) stands for trillions of floating-point operations per second. It’s a measurement unit used to express a computer system's computational power, especially in GPUs and supercomputers.
Combining the two, Tensor FP16 tracks how many 16-bit operations the computer can complete in a second. TLDR: It tracks the raw compute power of the machine.
Why Tensor FP16 is specifically important - Analysis of AI
FP16 is specifically important for two primary reasons: efficiency in deep learning models and the optimization of parallel processing.
Deep Learning Models: The rise of artificial intelligence and machine learning applications, particularly neural networks, has pushed the need for more efficient computation. FP16, or half-precision floating-point, is commonly used in deep learning because these models do not always require the full precision of FP32 or FP64 to maintain accuracy. Neural networks can often handle small rounding errors in calculations, so using FP16 allows more operations to be packed into a GPU's computational throughput without significantly impacting a model's performance.
Optimized Parallel Processing: In high-performance GPUs designed for AI workloads, such as NVIDIA's Tensor Core GPUs, FP16 computations allow for faster data processing while using less memory. This efficiency becomes critical when you're training large AI models, as the ability to conduct more operations simultaneously allows for quicker iterations and better resource utilization.
Plotting the Growth
Below, we now apply the growth in Teraflops of Tensor FP16 computing power to the same graph we originally produced.
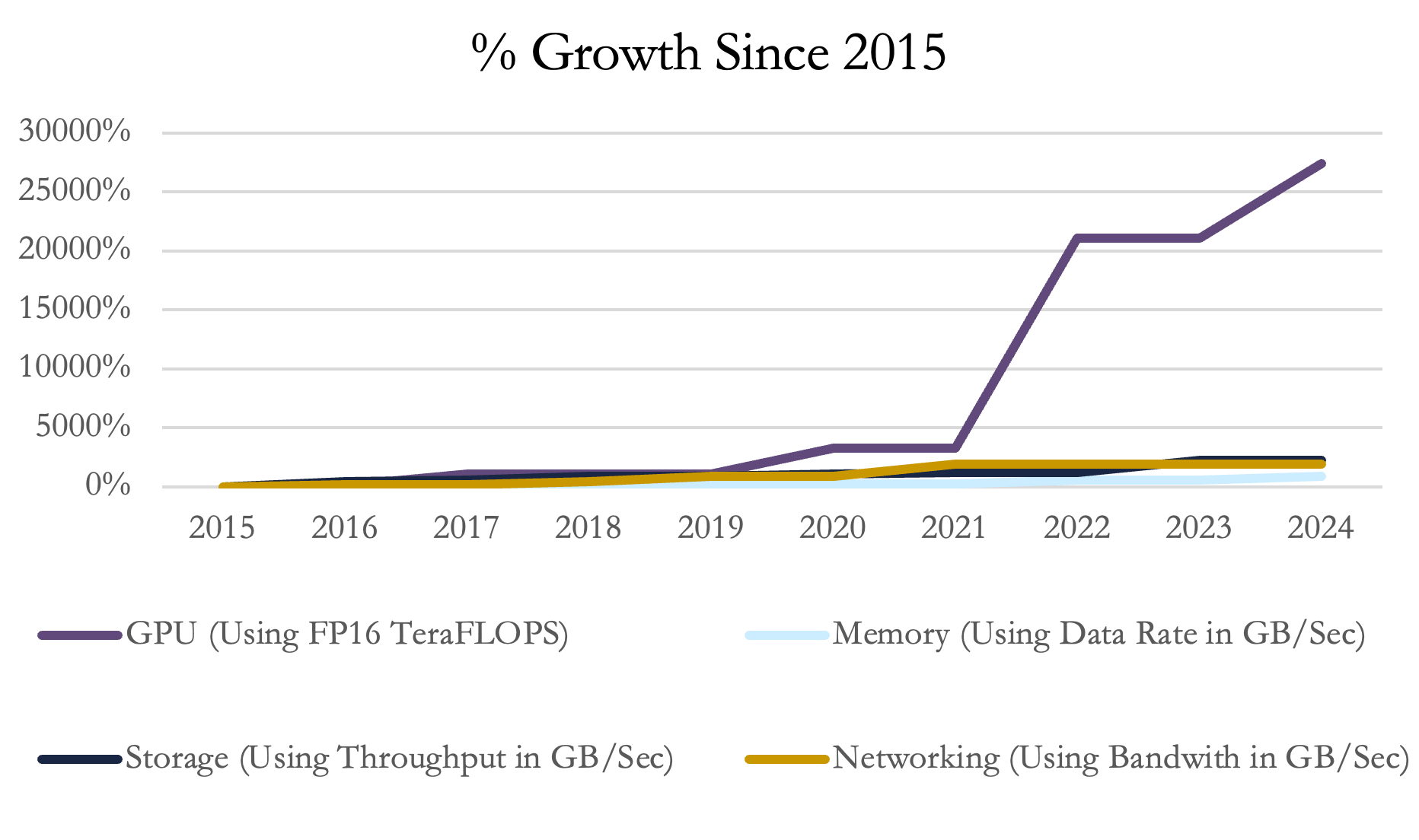
While the graph isn’t an exact apples-to-apples comparison (since we’re comparing different metrics), it clearly illustrates the incredible growth in GPU performance. In this period, NVIDIA released the Tesla K80 GPU, Tesla P100, Tesla V100, A100, and now famous H100 which are incredible optimizations of previous models. This has allowed Tensor FP16 performance to increase by a staggering 375x—dwarfing the improvements in memory, storage, and networking.
To put the GPU's progress into perspective, in 2015, the Tesla K80 could deliver 9.35 TFLOPs of FP16 performance, which was sufficient for running a modern video game like Call of Duty at full resolution on high settings. This is the same GPU that was training the first AI models. Fast forward to today, and the upcoming NVIDIA Blackwell is projected to be 375 times more powerful, training LLMs in a fraction of the time. This leap in efficiency is nothing short of extraordinary, highlighting just how far GPU technology has come in less than a decade.
Side Note: How has that driven the returns of companies?
What is additionally interesting as well is the plot of cumulative returns for key public players in each one of these industries.
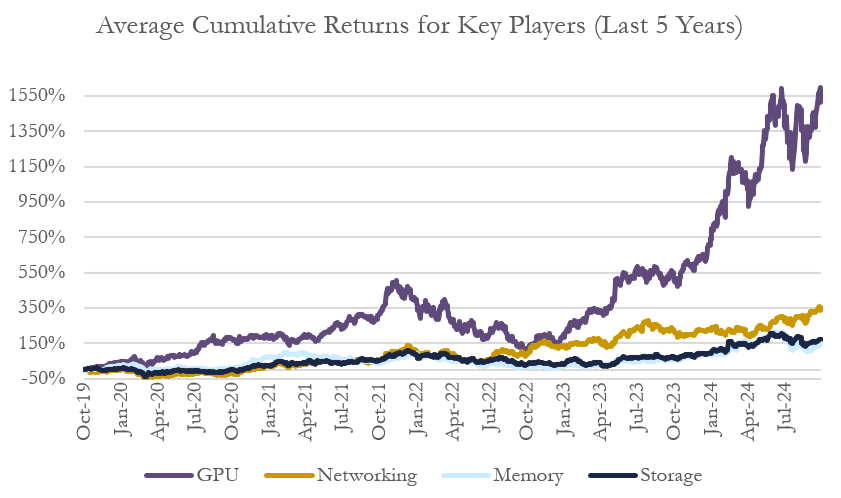
Over the past five years, GPU companies like NVIDIA have seen massive returns, while memory and storage companies have seen substantial returns less than that of the computing companies. This trend interestingly mirrors the uneven pace of innovation across these technologies that was shown above.
Key Note: Not all parts of the GPU have been optimized
It’s important to note that GPUs have primarily been optimized for AI workloads using FP16 operations.
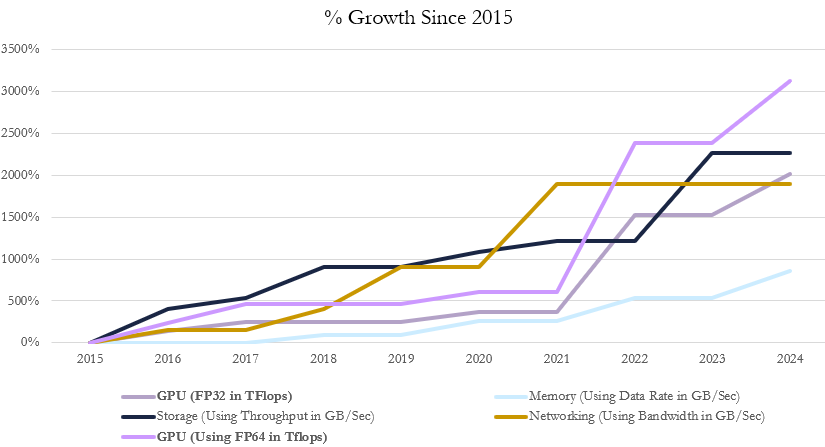
If we consider FP32 and FP64 operations—used in high-precision tasks like scientific computing—the growth in GPU performance is more in line with other components of the data center. FP32 and FP64 operations are more precise than FP16, which is why they’re used in areas where accuracy is critical.
Regardless, the overall growth trends reflect how semiconductors have consistently defied perceived limits, supporting Moore’s Law. Even in recent years, when many predicted a slowdown, the semiconductor industry has found ways to innovate—driving improvements across processing units, memory bandwidth, and data transfer rates.
The Opportunity
Thus, the opportunity presents itself. Is there a way that memory, networking, and storage can have a period of incredible optimization like the GPU did with the NVIDIA A100 and H100 GPUs? Gavin Baker does, as he seems to think that this is a great opportunity to invest in the next-generation data center.
If we can optimize these components, we stand to increase MFU dramatically. By closing the performance gap between GPUs and other infrastructure, we can ensure that the GPUs are working at their full potential, providing higher returns on investment in computing power and driving innovation forward.
This opportunity may be realized soon, as venture investment in startups has rebounded in 2024 compared to 2023.
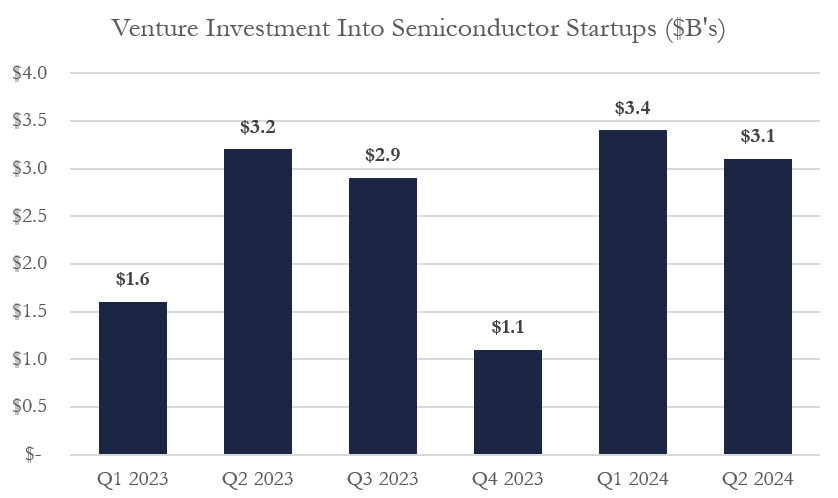
2024 is already off to a hot start with hundreds of semiconductor startups raising more than $6.5B in funds, and Q1 saw > 100% YoY growth in funding to semiconductor startups.
AI Hardware Companies dealing with all aspects of the server rack such as NVIDIA, Arm, and Micron have established venture arms and are looking to make investments in promising startups that create chips to optimize memory, storage, and networking to increase MFU.
Notable Startups to Watch
I will conclude this write-up by recognizing a couple of interesting startups in the semiconductor ecosystem that are seeking to solve the bottlenecking problems I have described.
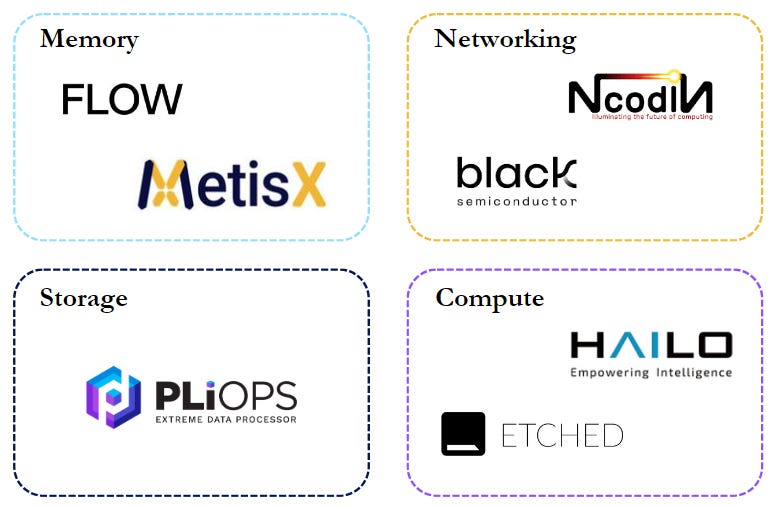
Memory
MetisX – Raised $44M to develop a memory-centric architecture based on CXL to overcome frequent memory access bottlenecks.
Flow Computing – Raised $4.3M for its Parallel Processing Unit (PPU), which boosts CPU performance by 100X by reducing memory latency and overlapping execution.
Networking
NcodiN – Raised €3.5M to develop optical interposer technology that allows for faster data transfer and higher bandwidth compared to electrical connections. Targets chipset-based disaggregated processors for high-performance AI workloads.
Black Semiconductor – Raised €254.4M for a graphene-based co-integrated optics system enabling parallel chip connectivity over long distances for data centers.
GPU
Etched – Raised $120M to build an algorithm-specific ASIC for transformer inference. Achieves over 90% MFU, running 500,000 Llama 70B tokens per second with eight Sohu chips in one server.
Hailo – Raised $120M for AI accelerators optimized for LLMs and neural networks at the edge, providing high efficiency and low power consumption, targeting AI vision and generative AI.
Storage
PliOps - Raised $100M as a data center startup that enhances SSD performance with its Storage Processing Unit (SPU), significantly boosting data throughput and reducing latency for enterprise storage solutions.
Conclusion
In conclusion, the future of AI hardware lies not just in the exponential growth of GPU performance but in addressing the bottlenecks across the entire data center ecosystem—memory, storage, and networking.
Gavin Baker's insights highlight the pressing need to optimize these systems to unlock the full potential of GPUs. As Baker mentioned:
“If you have a higher MFU, it means that you can choose between faster time to market, better quality, or lower costs.”
Thus, VCs and investors must realize that the entire server rack needs to innovate just as much as the GPU to maximize MFU and invest accordingly.
To put it simply: in the race for AI dominance, it’s not just about having the fastest engine—it’s about making sure the entire car can keep up with the speed.
Only real ones listened to the Gavin Baker invest like the best podcast